Yu Wang 王钰
Associate Professor
School of Artificial Intelligence
Shanghai Jiao Tong University
Shanghai AI Laboratory
Biography
Yu Wang is currently an Associate Professor at School of Artificial Intelligence, Shanghai Jiao Tong University (SJTU). Prior to SJTU, he was a Senior Research Associate working in the Machine Intelligence Laboratory, University of Cambridge, where he was working with Prof. Mark Gales, Prof. Phil Woodland and Dr. Kate Knill. He obtained his PhD study in Speech Processing in the Speech and Audio Processing Laboratory at Imperial College London, supervised by Mike Brookes. Following his graduation of PhD, he joined University of Cambridge as a Research Associate and started to work as a key member on the Automated Language Teaching and Assessment (ALTA) project (funded by Cambridge Assessment), on which we released an end-to-end deep learning-based automatic spoken language assessment platform Speak&Improve in 2019 and it is now officially suggested as the practising platform for Cambridge Linguskill international English test. Since 2019, he started to work on the Machine Translation for English Retrieval of Information in Any Language (MATERIAL) project (funded by IARPA), on which he was the technical lead for the spoken language processing contribution at CUED. His current research interests focus on Natural Language Processing, Multi-modal Dialogue System and Large Langage Model. He is an Action Editor of Neural Networks and regularly serves as an Area Chair in the major conferences including NeurIPS, ACL Rolling Review, ICASSP, and INTERSPEECH.
We cordially invite masters and doctoral students, as well as postdoctoral researchers in the fields of computer science and electronic information, to join our research group. Our group is also keen to welcome undergraduate students with a passion for AI research. Here, we offer a vibrant and innovative learning environment where you can explore AI with outstanding peers, learning and growing together. If you are interested in joining us, please contact me.
实验室长期诚邀计算机与电子信息领域的硕士、博士研究生,以及博士后研究人员。同时,我们也非常欢迎对科研有兴趣的本科生加入我们的研究团队。这里提供一个充满活力和创新的学习环境,你可以与优秀的同学们一起探索人工智能,共同学习和成长。如果您有意加入我们,请与我联系。
Positions
- 2024 - Present, Associate Professor, School of Artificial Intelligence,
Shanghai Jiao Tong University - 2020 - 2024, Associate Professor, Cooperative Medianet Incorporative Center,
Shanghai Jiao Tong University - 2019 - 2020, Senior Research Associate, Machine Intelligence Laboratory,
University of Cambridge - 2015 - 2019, Research Associate, Machine Intelligence Laboratory,
University of Cambridge
- Natural Language Processing
- Speech and Language
- Multimedia Computing
Doctor of Philosophy, 2011 – 2015
Imperial College London, Department of EEE
Master of Science (MSc), 2009 – 2010
Imperial College London, Department of EEE
Bachelor of Engineering (BEng), 2005 – 2009
Huazhong University of Science and Technology, Department of EIE
Experience
News
Projects

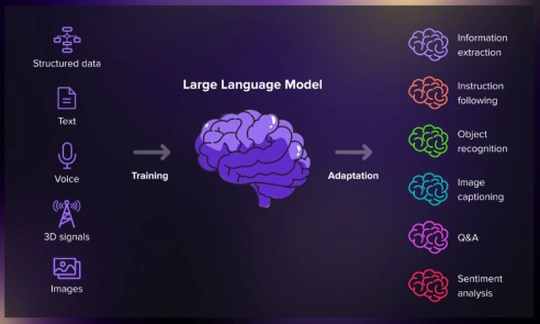
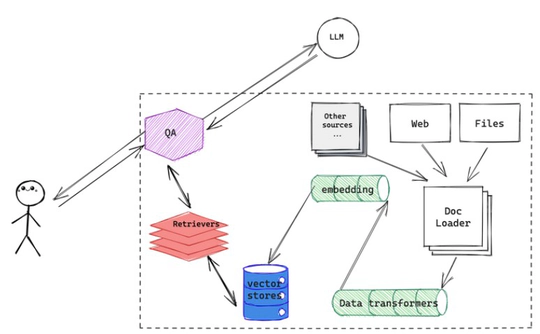
Recent Publications (2023 Onwards)
* indicates corresponding authors
Teaching
Contact
- yuwangsjtu@sjtu.edu.cn
- 1954 Huashan Road, Shanghai Jiao Tong University, Shanghai, 200030
- Room 315, School of Artificial Intelligence, Xuhui Campus