Multimodal dialogue and perception
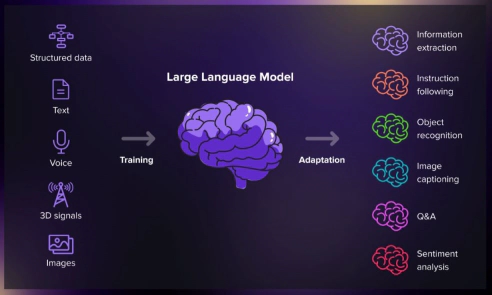 The illustration of multimodal dialogue.
The illustration of multimodal dialogue.The Multimodal Perception and Dialogue group specializes in advancing technologies in video dialogues and speech recognition, marking significant strides in artificial intelligence and machine learning. The group’s endeavor is to revolutionize machine interaction by integrating visual and auditory information, thus facilitating a more intuitive and natural communication between humans and technology.
In video dialogue technology, the group develops algorithms that allow for intelligent conversation based on video content. This involves understanding the visual context—identifying objects, actions, and the scene’s overall narrative—to produce relevant and coherent dialogue responses. The approach is rooted in deep learning, enabling the processing of complex video data and fostering a human-like interaction model with machines.
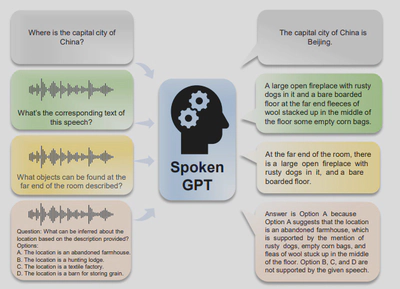
Collectively, the efforts of the Multimodal Perception and Dialogue group are geared towards redefining the capabilities of machines in perceiving, understanding, and interacting with the world. The integration of video and audio signals opens new horizons for enhancing human-computer interaction and creating more accessible communication aids, potentially transforming numerous sectors including education, healthcare, and customer service.pharetra. Nulla congue rutrum magna a ornare.
Aliquam in turpis accumsan, malesuada nibh ut, hendrerit justo. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Quisque sed erat nec justo posuere suscipit. Donec ut efficitur arcu, in malesuada neque. Nunc dignissim nisl massa, id vulputate nunc pretium nec. Quisque eget urna in risus suscipit ultricies. Pellentesque odio odio, tincidunt in eleifend sed, posuere a diam. Nam gravida nisl convallis semper elementum. Morbi vitae felis faucibus, vulputate orci placerat, aliquet nisi. Aliquam erat volutpat. Maecenas sagittis pulvinar purus, sed porta quam laoreet at.